Một trong những case study mà bạn có thể gặp đó là lấy dữ liệu từ những website khác và lưu vào database của riêng mình dùng để làm những trang như tổng hợp link, tin tức.
Mọi thứ sẽ dễ dàng nếu trang nguồn cung cấp API hoặc RSS. Còn với những trang không cung cấp thì sao? Lúc này chúng ta có thể sử dụng kỹ thuật gọi là web scraping.
web scraping hiểu đơn giản là tải nội dung một trang web, sau đó lấy những thông tin cần thiết từ nó.
Puppeteer
Trong bài viết này, chúng ta sẽ sử dụng Puppeteer là một thư viện Node.js giúp chúng ta tạo một headless Chrome .
Các bạn có thể tham khảo thư viện này trên Github.
puppeteer/puppeteer
Node.js API for Chrome
- Star83255
- Fork8938
- Issues279
- Updatedtháng 5 19, 2023
Lấy dữ liệu
Case study chúng ta là lấy những bài viết chất lượng 😂 từ 12bit.vn (dã sử trang này không chịu cung cấp API / RSS).
Đầu tiên, chúng ta sẽ cài đặt Puppteer:
npm install puppteer
Trong file index.js bạn require thư viện:
const puppteer = require('puppteer');
Tiếp theo, chúng ta sẽ khởi tạo một browser sử dụng phương thức launch() và truy cập vào trang https://12bit.vn
như sau:
(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://12bit.vn')
// ...
})()
Vì các method như launch(), newPage() trả về một Promise, vì vậy để cho code trông tuần tự dễ nhìn, chúng ta sẽ sử dụng await/async. Ngoài ra ở đây mình cũng dùng IIFE
để invoke function ngay lập tức khi file được thực thi.
Bước cuối cùng, chúng ta sẽ lấy nội dung của trang web bằng cách gọi tới page.evaluate. Phương thức này nhận vào một callback function, trong callback function đó, chúng ta có thể lấy được những gì mình muốn thông qua document và tất cả browser APIs.
Bây giờ thì quay qua 12bit.vn một chút, chúng ta xem thử làm thế nào để lấy được title và url của một bài viết.
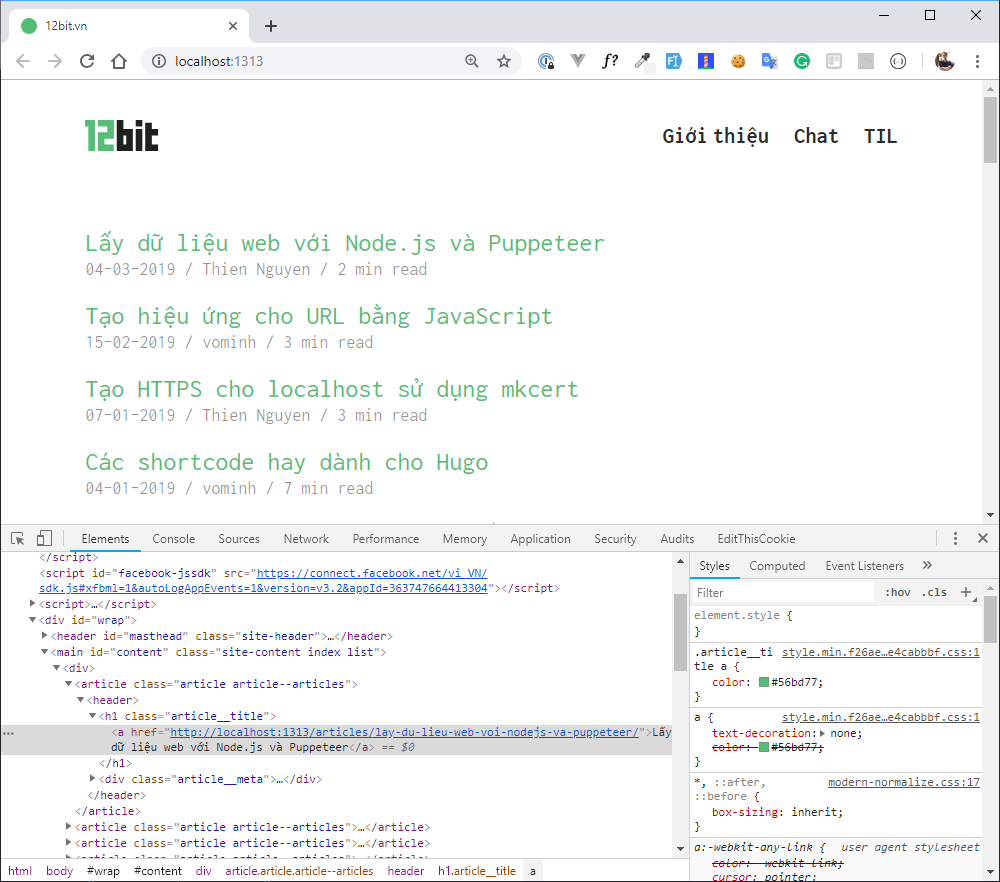
Nếu nhìn vào bức hình bên trên chúng ta sẽ dễ dàng lấy được title và url bằng cách query tất cả node a nằm trong h1.article__title
document.querySelectorAll('.article__title a')
// NodeList(33) [a, a, a, a, a, a, a, a, a, a, a, a, a,...]
Việc còn lại chỉ cần lặp qua danh sách NodeList và lấy title bằng innerText và url bằng getAttribute('href')
Đoạn code hoàn chỉnh như sau:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://12bit.vn')
const results = await page.evaluate(() => {
let items = document.querySelectorAll('.article__title a')
let links = []
items.forEach((item) => {
links.push({
title: item.innerText,
url: item.getAttribute('href'),
})
})
return links;
});
console.log(results)
// Do what you want with the `results`
await browser.close()
})()
Kết quả:
$ node app.js
[ { title: 'Tạo hiệu ứng cho URL bằng JavaScript',
url: 'https://12bit.vn/articles/tao-hieu-ung-cho-url-bang-javascript/' },
{ title: 'Tạo HTTPS cho localhost sử dụng mkcert',
url: 'https://12bit.vn/articles/tao-https-cho-localhost-su-dung-mkcert/' },
{ title: 'Các shortcode hay dành cho Hugo',
url: 'https://12bit.vn/articles/cac-shortcode-hay-cho-gohugo/' },
{ title: 'Xử lý khi không load được ảnh bằng cách sử dụng service worker',
url: 'https://12bit.vn/articles/xu-li-anh-khi-khong-load-duoc-ban-service-worker/' },
{ title: 'Xây dựng 3D button trong Flutter',
url: 'https://12bit.vn/articles/xay-dung-3d-button-trong-flutter/' },
...
Kết luận
Ví dụ trên là một trong những tính năng mà Puppeteer mang lại. Ngoài ra các bạn có thể dùng nó để làm các việc sau:
- Screenshot 1 trang web
- Trích xuất 1 tran web ra định dạng PDF
- Form submission, UI testing
- Test chrome extensions
Ví dụ thì vậy thôi, chứ tụi mình có cung cấp RSS nha https://12bit.vn/index.xml